


Аpple теперь выпустил чипы M1 Apple кремний, и после весь пух может быть удивительно что отличает его от Intel или AMD процессора? Вы, наверное, слышали, что M1 называют процессором ARM, и что ARM — это так называемый процессор RISC, в отличие от процессоров x86 от Intel и AMD.
Если вы попытаетесь прочитать о разнице между микропроцессорами RISC и CISC, вы услышите, как многие люди говорят вам, что RISC и CISC больше не имеют значения. Что они по сути одинаковы. Но так ли это на самом деле?
Итак, вы запутались и хотите получить прямые ответы. Что ж, тогда эта статья — подходящее место для вас.
Я пролистал массу комментариев и написал по этому поводу, иногда самими инженерами, создавшими эти чипы, так что вам не нужно тратить на это время.
Сначала я начну с некоторых основ, которые вы должны понять, прежде чем мы начнем отвечать на некоторые более глубокие вопросы, такие как RISC против CISC. Я вставляю заголовки, чтобы вы могли пропустить то, что уже знаете.
Вот некоторые из тем, которые я затрону в этой статье:
- Что такое ЦП?
- Что такое архитектура набора команд (ISA)
- Зачем выбирать одну ISA вместо другой?
- Чем отличаются наборы инструкций RISC и CISC?
- Философия CISC
- Философия RISC
- Конвейерная обработка
- Загрузить / сохранить архитектуру
- Сжатые наборы команд
- Микрокод против микроопераций
- Чем микрооперация отличается от инструкции RISC?
- Гиперпоточность / Аппаратные потоки
- Имеет ли смысл RISC vs CISC?
Что такое микропроцессор (ЦП)?
Разъясним, что такое микропроцессор. Вы, наверное, уже имеете какое-то представление, иначе вы бы не щелкнули по этой статье.
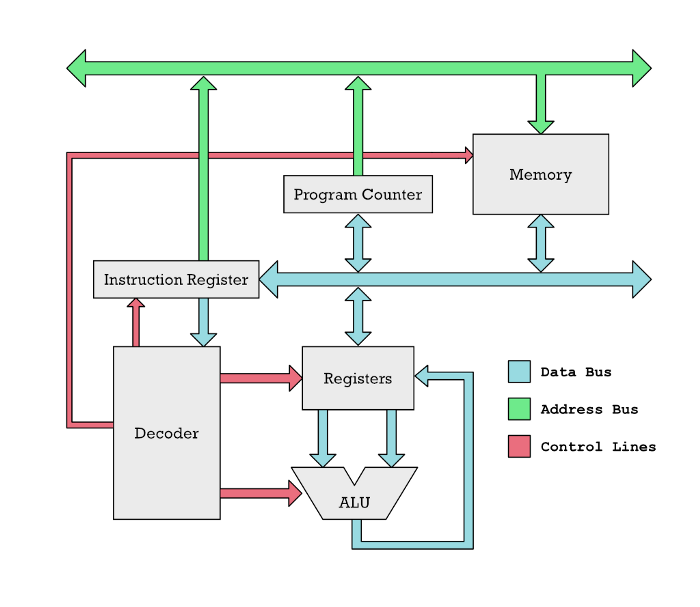
Центральный процессор — это мозг компьютера. Он читает инструкции из памяти, сообщая компьютеру, что делать. Эти инструкции представляют собой просто числа, которые нужно интерпретировать определенным образом.
В памяти нет ничего, что помечает число как просто число или, в частности, инструкцию. Вместо этого создатели операционной системы и программ должны убедиться, что инструкции и данные помещены в места, где ЦП ожидает найти программный код и данные.
Микропроцессоры (ЦП) делают очень простые вещи. Вот пример инструкций, которым следует ЦП:
загрузить r1, 150
загрузить r2, 200
добавить r1, r2
сохранить r1, 310
Это удобочитаемая форма того, что могло бы быть просто списком чисел на компьютере. Например load r1, 150, в типичном процессоре RISC он будет представлен одним 32-битным числом. Это означает число из 32 цифр, где каждая цифра должна быть 0 или 1.
loadв первой строке перемещает содержимое ячейки памяти 150 для регистрации r1. Память вашего компьютера (RAM) — это набор миллиардов чисел. У каждого из этих номеров есть адрес (расположение), так что ЦП может выбрать правильный.

Далее вы можете задаться вопросом, что такое регистр . На самом деле это довольно старая концепция. Старые механические кассовые аппараты в круглосуточных магазинах также имели концепцию регистров . В то время регистр был чем-то вроде механического приспособления, в котором хранился номер, с которым вы хотите работать. Часто у него был аккумулятора, в регистр который вы могли добавлять значения. Он будет отслеживать сумму.
Ваш электронный калькулятор такой же. Большую часть времени на дисплее вы видите содержимое аккумулятора. Вы делаете кучу вычислений, которые влияют на содержимое аккумулятора.
ЦП такие же. У них есть несколько регистров, которым часто дают простые имена, такие как A, B, C или r1, r2, r3, r4 и т. Д. Команды ЦП обычно выполняют операции с этими регистрами. Они могут складывать два числа, хранящихся в разных регистрах.
В нашем примере add r1, r2содержимое складывается r1и r2вместе, а результат сохраняется в r1.
Наконец, мы хотим сохранить результат в памяти (RAM) store r1, 310, которая хранит результат в ячейке памяти с адресом 310.
Что такое архитектура набора команд (ISA)?
Как вы понимаете, процессор понимает ограниченное количество инструкций. Если вы знакомы с обычным программированием, в котором вы можете определять свои собственные функции, машинный код не такой.
Существует фиксированное количество инструкций, которые понимает ЦП. Вы как программист не можете пополнить этот набор.
Существует большое количество разных процессоров, и не все они используют один и тот же набор инструкций. Это означает, что они не будут одинаково интерпретировать числа для инструкций.
В одной архитектуре ЦП 501012может означать, add r10, r12а в другой — load r10, 12. Комбинация инструкций, которые понимает процессор, и регистров, о которых он знает, называется архитектурой набора инструкций (ISA).
Например, чипы Intel и AMD понимают x86 ISA. Хотя, например, чипы, которые Apple использует в своих устройствах iPhone и iPad, таких как A12, A13, 14 и т. Д., Все понимают ARM ISA. И теперь мы можем добавить M1 в этот список.
Эти чипы мы называем Apple Silicon. Они используют ARM ISA, как и многие другие мобильные телефоны и планшеты. Даже игровые консоли, такие как Nintendo и самые быстрые в мире суперкомпьютеры, используют ARM ISA.
x86 и ARM не взаимозаменяемы. Компьютерная программа будет скомпилирована для определенного ISA, если это не JavaScript, Java, C # или аналогичный. В этом случае программа компилируется в байтовый код, который является ISA-подобным процессору, но для процессора, которого на самом деле не существует. Вам нужен своевременный компилятор или интерпретатор, чтобы преобразовать этот составленный набор инструкций в фактический набор инструкций, используемый в процессоре вашего компьютера.
Это означает, что большинство современных программ на Apple Mac не будут работать сразу после установки на новых Mac на базе Apple Silicon. Текущие программы состоят из инструкций x86. Для решения этой проблемы программы должны быть перекомпилированы для новой ISA. И у Apple есть козырь в рукаве с Rosetta 2, программой, которая переводит инструкции x86 в инструкции ARM перед ее запуском.
Зачем переходить на совершенно другую ISA?
Теперь следующий вопрос. Зачем использовать новую ISA для своих Mac? Почему Apple не могла просто заставить свой Apple Silicon понимать инструкции x86? Никакой перекомпиляции или перевода с помощью Rosetta 2 не требуется.
Что ж, оказывается, не все наборы инструкций созданы равными. ISA процессора сильно влияет на то, как вы можете спроектировать сам процессор. Конкретный ISA, который вы используете, может усложнить или упростить задачу по созданию высокопроизводительного процессора или процессора, потребляющего мало энергии.
Второй вопрос — лицензирование. Apple не может свободно создавать собственные процессоры с 86 ISA. Это часть интеллектуальной собственности Intel, и им не нужны конкуренты. Компания ARM, напротив, на самом деле не создает свои собственные процессоры. Они просто разрабатывают ISA и предоставляют эталонные проекты процессоров, реализующих эту ISA.
Следовательно, ARM позволяет делать практически то, что вы хотите. Этого хочет Apple. Они хотят создавать индивидуальные решения для своих компьютеров со специализированным оборудованием для обработки таких вещей, как машинное обучение, шифрование и распознавание лиц. Если вы используете x86, вам придется делать все это на внешних чипах. По соображениям эффективности Apple хочет сделать все это в одной большой интегральной схеме или в том, что мы называем системой на кристалле (SoC) .
Эта разработка началась на смартфонах и планшетах. Они слишком малы, чтобы иметь много разных отдельных чипов на какой-нибудь большой материнской плате . Вместо этого они должны объединить все, что обычно расположено на одной материнской плате, в один чип, содержащий ЦП, ГП, память и другое специализированное оборудование.
Теперь эта тенденция распространяется на ноутбуки и, вероятно, позже на настольные ПК. Тесная интеграция дает лучшую производительность, и здесь x86 с их негибкой схемой лицензирования является большим недостатком.
Но давайте не будем сбивать с толку то, о чем в первую очередь посвящена эта статья: RISC vs CISC. Архитектуры наборов инструкций, как правило, следуют разным основным принципам определения ISA. x86 — это то, что мы называем архитектурой CISC. В то время как ARM следует философии RISC. Это большая разница. Итак, давайте углубимся в ключевое отличие.

В чем разница между наборами инструкций RISC и CISC?
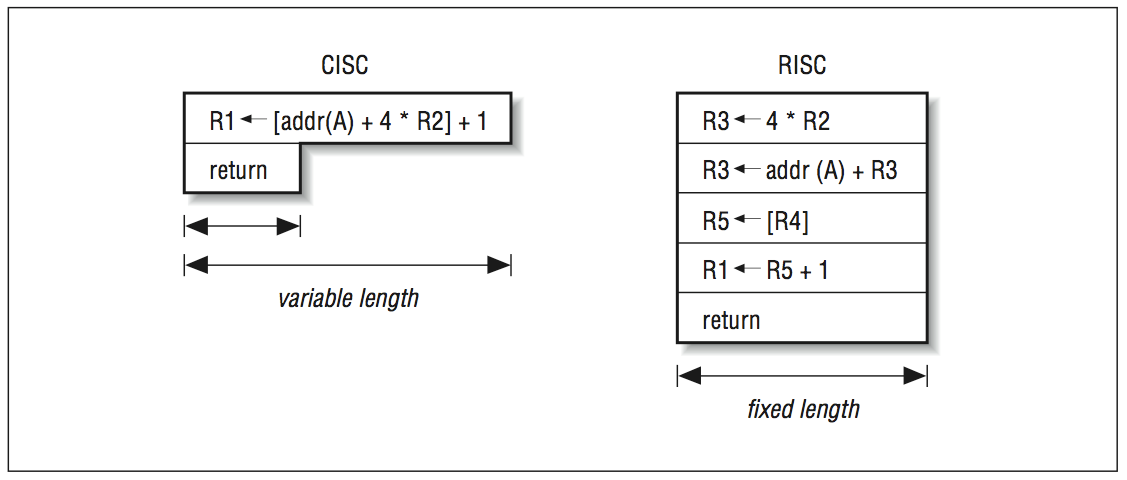
CISC означает компьютер со сложным набором команд , а RISC — компьютер с сокращенным набором команд .
Объяснить, в чем разница сегодня, труднее, чем когда впервые появился RISC, потому что и RISC, и процессор CISC украли идеи друг у друга, и была проведена интенсивная маркетинговая кампания с интересом размыть различия.
Обход маркетинговой дезинформации
Пол ДеМоне написал возникло эту статью еще в 2000 году, которая дает некоторое представление о маркетинговом давлении, которое на раннем этапе.
Еще в 1987 году вершиной линейки процессоров x86 был Intel 386DX, а вершиной линейки RISC-процессоров был MIPS R2000 .
Несмотря на то, что у процессора Intel было больше транзисторов, 275 000 против 115 000 на MIPS и вдвое больше кеш-памяти, в тестах производительности процессор x86 был полностью снесен.
Оба процессора работали с тактовой частотой 16 МГц, но процессор RISC имел в 2–4 раза более высокую производительность, в зависимости от используемого теста.
Поэтому неудивительно, что к началу 90-х стало общепринятым представление о том, что процессоры RISC имеют значительно лучшую производительность.
Таким образом, у Intel начались проблемы с восприятием на рынке. У них были проблемы с убеждением инвесторов и покупателей в том, что их устаревшая конструкция CISC может превзойти процессор RISC.
Таким образом, Intel начала продавать свои чипы как RISC-процессоры с простой стадией декодирования, которая превращала инструкции CISC в инструкции RISC.
Таким образом, Intel могла бы представить себя привлекательно: они сказали бы, что с нашими чипами вы по-прежнему получаете технологически более совершенные процессоры RISC, но наши процессоры RISC понимают инструкции x86, которые вы уже знаете и любите.
Но сразу проясним: в чипах x86 нет внутреннего RISC. Это просто маркетинговый ход. Боб Колвеллс, один из главных создателей процессора Intel Pentium Pro, считающегося чипом с RISC внутри, поясняет сам это .
Однако вы увидите, как эта ложь распространяется по всему Интернету, потому что Intel действительно хорошо продвигала этот маркетинговый ход. Это работает, потому что в этом есть полуправда. Но для того, чтобы действительно понять RISC и CISC, вам действительно нужно начать с отказа от этого мифа.
Думая, что процессор CISC может иметь внутри процессор RISC, вы только запутаетесь в разнице между RISC и CISC.
Философия CISC
Хорошо, с этой напыщенной речью, давайте посмотрим, что на самом деле представляют собой RISC и CISC. Оба основаны на философии проектирования процессора.
Давайте начнем с рассмотрения философии CISC. CISC сложнее определить, поскольку микросхемы, которые мы обозначаем как CISC, имеют большое разнообразие конструкций. Но мы все же можем говорить о некоторых общих закономерностях.
Еще в конце 1970-х, когда начали разрабатывать CISC-процессоры, память все еще была очень дорогой. Компиляторы тоже были очень плохими, и люди, как правило, писали программы на ассемблере вручную.
Поскольку память стоит дорого, вам нужно найти способы ее сохранить. Для этого нужно было придумать действительно мощные инструкции процессора, которые могли бы делать много всего.
Это также помогло программистам на ассемблере, поскольку им было легче кодировать программы, поскольку всегда была какая-то единственная инструкция, которая делала то, что они хотели.
Через некоторое время это стало действительно сложным. Создание декодеров для всех этих инструкций стало проблемой. Первоначально они решили эту проблему с помощью изобретения микрокода .
Вы знаете, что в программе можно избежать повторения общих задач, поместив их в отдельную подпрограмму (функцию), которую вы можете вызывать повторно.
Идея микрокода была аналогичной. Для каждой инструкции машинного кода в ISA вы создаете небольшую программу, хранящуюся в специальной памяти внутри ЦП, состоящую из гораздо более простых инструкций, называемых микрокодом.
Таким образом, ЦП будет иметь небольшой набор простых инструкций микрокода. Затем они могли бы добавить множество дополнительных инструкций ISA, просто добавив новые небольшие программы микрокода внутри процессора.
Это имело дополнительное преимущество, заключающееся в том, что память, содержащая эти программы микрокода, была постоянным запоминающим устройством (ПЗУ), которое в то время было намного дешевле, чем ОЗУ. Следовательно, сокращение использования ОЗУ за счет увеличения использования ПЗУ было экономическим компромиссом.
Так что какое-то время все выглядело действительно хорошо в стране CISC. Но со временем у них начались проблемы. Все эти программы на микрокоде стали проблемой. Иногда они допускали ошибку программирования. Исправление ошибки в программе с микрокодом было намного труднее, чем исправление ошибки в обычной программе. Вы не можете получить доступ к этому коду и протестировать его, как вы получаете доступ и тестируете обычное программное обеспечение.
Некоторые люди начали думать: должен быть более простой способ справиться с этим беспорядком!
Философия RISC
Оперативная память стала дешевле, компиляторы стали лучше, и люди больше не программировали на ассемблере.
Это изменение технологического ландшафта привело к возникновению философии RISC.
Они начали замечать, анализируя программы, что сложные инструкции, которые были добавлены в CISC, мало использовались людьми.
Разработчикам компиляторов также было сложно выбрать одну из этих сложных инструкций. Вместо этого они предпочли комбинировать более простые инструкции для выполнения работы.
Можно сказать, что у нас есть случай правила 80/20. Примерно 80% времени было потрачено на выполнение 20% инструкций.
Итак, идея RISC заключалась в следующем: давайте откажемся от сложных инструкций и заменим их меньшим количеством простых инструкций. Вместо отладки и исправления программ микрокода, что сложно. Вы предоставляете разработчикам компилятора решать проблемы.
Есть некоторые разногласия по поводу того, что словом « сокращение» следует понимать под по отношению к RISC. Это было интерпретировано как уменьшение количества инструкций. Но более разумная интерпретация заключается в том, что это означает снижение сложности инструкции. То есть сами инструкции сделаны проще. Это не обязательно означает простой вид с точки зрения пользователя, а скорее простоту реализации на оборудовании и, предпочтительно, использование нескольких ресурсов ЦП одновременно.
Код RISC не обязательно проще писать человеку. Я совершил эту ошибку много лет назад, когда думал, что сэкономлю время на написании кода сборки, используя инструкции PowerPC (архитектура IBM RISC с множеством инструкций). Это дало мне много лишней работы и разочарований.
Одним из ключевых аргументов в пользу RISC было то, что люди перестали писать ассемблерный код от руки, и вам нужен набор инструкций, с которым компиляторам было бы легко иметь дело. RISC оптимизирован для компиляторов, не обязательно для людей.
Хотя определенные наборы инструкций RISC в некотором смысле может показаться более легким в написании для человека, потому что есть намного меньше инструкций для изучения. С другой стороны, вам обычно приходится писать больше инструкций, чем если бы вы использовали набор инструкций CISC.
Конвейерная обработка: инновация RISC
Другой ключевой идеей RISC была конвейерная обработка. Позвольте мне привести простую аналогию, чтобы объяснить, о чем идет речь.
Подумайте о покупках в продуктовом магазине. Сейчас это работает немного по-разному в каждой стране, но я основываю это на том, как это работает в моей родной Норвегии. Вы можете разделить действия на кассе на несколько этапов:
- Поместите купленные товары на конвейерную ленту и просканируйте их.
- Воспользуйтесь платежным терминалом для оплаты только что отсканированных товаров.
- Упакуйте только что оплаченные товары в пакеты.


Если бы это произошло не конвейерным способом, как первоначально работало большинство процессоров CISC, то следующий покупатель не начал бы выкладывать свои продукты на конвейерную ленту, пока вы не соберете все свои продукты и не уйдете.
Это неэффективно, потому что конвейерная лента может использоваться для сканирования предметов во время упаковки. Во время упаковки можно использовать даже платежный терминал. Таким образом, ресурсы используются недостаточно.
Мы можем думать о каждом шаге как о такте или единице времени. Это означает, что для обработки каждого клиента требуется 3 единицы времени. Таким образом, за 9 единиц времени вы обработали только 3 клиентов.
Однако мы могли бы конвейерно этот процесс. Как только я начну работать с платежным терминалом, следующий покупатель сможет класть свои продукты на ленту конвейера.
Когда я начал собирать вещи, этот покупатель мог использовать платежный терминал, которым я только что закончил пользоваться. В этот момент третий покупатель мог начать выкладывать продукты на конвейерную ленту.
Результатом такого подхода является то, что каждый раз, когда кто-то заканчивает упаковывать еду и уезжает со своими продуктами. Таким образом, за 9 единиц времени вы обработаете 6 клиентов. По мере увеличения времени вы приближаетесь к обработке одного клиента всего за 1 единицу времени, и все это благодаря конвейерной обработке. Это 9-кратное ускорение.
Мы могли бы описать использование кассового аппарата как имеющего задержку в 3 единицы времени, но пропускную способность одной покупки на 1 единицу времени.
В терминологии микропроцессора это будет означать, что 1 инструкция имеет задержку 3 тактовых цикла, но средняя пропускная способность 1 инструкция за тактовый цикл.
В этот пример я вложил несколько предположений, а именно, что каждый этап оформления заказа занимает одинаковое количество времени. Чтобы положить продукты на ленту конвейера, потребовалось примерно столько же времени, сколько и для работы с платежным терминалом или упаковки продуктов.
Если время сильно различается для каждого этапа, это не сработает. Например, если у кого-то на конвейерной ленте много продуктов, то платежный терминал и зона упаковки долгое время остаются неиспользуемыми, что снижает эффективность всего этого.
Дизайнеры RISC это понимали. Таким образом, они попытались стандартизировать продолжительность каждой инструкции и разбить ее действия на этапы, которые занимают примерно одинаковое время. Таким образом, каждый ресурс внутри ЦП может постоянно использоваться по максимуму по мере обработки инструкций.
Например, если мы посмотрим на процессор ARM RISC, он имеет 5-ступенчатый конвейер для обработки инструкций:
- Извлечь инструкцию из памяти и обновить счетчик программы, чтобы иметь возможность выбрать следующую инструкцию в следующем тактовом цикле.
- расшифровке Инструкция по . То есть выяснить, что он должен делать. Это означает активацию различных электрических проводов для переключения различных частей процессора, которые мы используем для выполнения инструкции.
- Выполнение включает использование арифметико-логического блока (ALU) или выполнение операций сдвига.
- Память Доступ к данным в памяти, если это необходимо. Вот что
loadсделала бы инструкция. - Запишите результаты предыдущей операции в соответствующий регистр.
В инструкциях ARM есть разделы, посвященные каждой из этих частей, и каждый этап обычно занимает 1 тактовый цикл. Это упрощает передачу инструкций ARM по конвейеру.
Например, поскольку каждая инструкция имеет одинаковый размер, Fetch этап знает, как получить следующую инструкцию. Его не нужно сначала декодировать.
С инструкциями CISC это сложно. Инструкции могут быть переменной длины. Таким образом, вы не знаете, пока не расшифруете части инструкции, где будет следующая инструкция.
Вторая проблема заключается в том, что инструкции CISC могут иметь произвольную сложность. Выполнение множественных обращений к памяти и выполнение целого ряда вещей, что означает, что вы не можете легко разделить инструкцию CISC на четко отдельные части, которые могут выполняться поэтапно.
Конвейерная обработка была убийственной функцией, которая действительно заставляла ранние процессоры RISC снижать производительность своих аналогов CISC.
Загрузить / сохранить архитектуру
Чтобы количество циклов, необходимых для каждой инструкции, было относительно единообразным и предсказуемым, чтобы все было удобно для конвейера, RISC ISA четко отделяют загрузку и сохранение в памяти от других инструкций.
В CISC, например, инструкция может загружать данные из памяти, выполнять сложение, умножение или что-то еще и записывать результат обратно в память.
В мире RISC это вообще большой запрет. Операции RISC, такие как сложение, сдвиг, умножение и т. Д., Обычно работают только с регистрами. У них нет доступа к памяти.
Это важно для работы трубопроводов. В противном случае инструкции в конвейерах могут иметь между собой всевозможные зависимости.
Несколько регистров для предотвращения раздувания памяти
Большая проблема для RISC по сравнению с CISC заключается в том, что с более простыми инструкциями требуется больше инструкций, а память, хотя и не дорогая, работает медленно. Если программа RISC потребляет намного больше памяти, чем программа CISC, она может работать намного медленнее, потому что ЦП постоянно ожидает медленного чтения памяти.
Разработчики RISC сделали несколько замечаний, чтобы решить эту проблему. Они заметили, что многие инструкции на самом деле просто перемещают данные в память и из нее для подготовки к различным операциям. Имея большее количество регистров, они могли сократить количество операций записи данных обратно в память.
Это потребовало улучшений в компиляторах. Компиляторы должны были хорошо анализировать программы и понимать, когда они могут хранить переменные в регистре, а когда их нужно записывать обратно в память. Работа с тоннами регистров стала для компиляторов важной задачей, позволяющей ускорить работу RISC-процессоров.
Потому что инструкции RISC были проще. Было не так много разных режимов адресации, с которыми нужно было иметь дело, например, было больше битов, доступных среди 32 бит для всей инструкции, чтобы указать номер регистра.
Это важно понимать. ЦП легко может иметь сотни регистров. Это не имеет большого значения. Не требует много транзисторов. Проблема в том, что в инструкции достаточно битов для решения каждой из них. x86, например, может оставить только 3 бита для определения каждого регистра. Это дало только ²³ = 8 регистров. RISC-процессоры, сохраняющие много битов, используемых для режимов адресации, могли позволить 5 битов для указания регистров, давая им ²⁵ = 32 из них. Очевидно, это варьируется. Но, похоже, так было обычно.
Продолжаю писать режим адресации, не объясняя, что это такое. По сути, это разные способы получения данных. Например, указав константу, представляющую адрес, используя абсолютный или относительный адрес. Использование содержимого регистра в качестве адреса и т. Д. ЦП CISC имели инструкции, которые позволяли вам, например, добавлять числа, найденные в ячейках памяти, в дополнение к значениям, закодированным в самой инструкции или в другом регистре. RISC делает это просто. Доступ к памяти осуществляется только инструкциями загрузки и сохранения.
Сжатые наборы команд
Сжатые наборы инструкций — относительно новая идея в мире RISC, призванная уменьшить проблему раздувания памяти, с которой RISC сталкивается при конкуренции с CISC.
Поскольку он новый, ARM пришлось модернизировать его, поскольку ARM изначально не проектировалась с учетом этого, в то время как современный RISC-V ISA имеет сжатый набор инструкций, разработанный с самого начала.
Это поворот идеи CISC. Помните, что в CISC могут быть очень короткие и очень длинные инструкции.
RISC не может легко добавить короткие инструкции, так как это усложняет работу конвейеров. Вместо этого дизайнеры пришли к идее сжатых инструкций.
В основном это означает, что часто используемое подмножество обычных 32-битных инструкций помещается в 16-битные инструкции. Таким образом, каждый раз, когда RISC-процессор выбирает инструкцию, он на самом деле потенциально выбирает две инструкции.
Например, в RISC-V будет специальный флаг, указывающий, есть ли сжатая инструкция или нет. Если он сжат, он будет распакован на две отдельные 32-битные инструкции.
Это важно, потому что это означает, что остальная часть ЦП может работать в обычном режиме. Он видит одни и те же красивые унифицированные 32-битные инструкции, где все различные этапы закодированы в предсказуемых стандартных местах.
Следовательно, сжатые инструкции не добавляют никаких новых инструкций. Это сильно зависит от умных ассемблеров или компиляторов. Сжатая инструкция имеет меньше доступных битов и, следовательно, не может выполнять все вариации того, что может делать 32-битная инструкция.
Следовательно, сжатая инструкция может иметь доступ только к 8 наиболее часто используемым регистрам. Не все 32. Возможно, я не смогу загрузить константы с одинаковым большим числом или смещения памяти.
Таким образом, ассемблер или компилятор должен решить, можно ли упаковать конкретную пару инструкций вместе или нет. Ассемблеру придется искать возможности для выполнения сжатия.
Так что, хотя это немного похоже на CISC, на самом деле это не так. Остальная часть ЦП, конвейер и т. Д. Видит те же 32-битные инструкции, что и обычно.
В ARM вам даже нужно переключить режим для выполнения сжатых инструкций. Сжатый набор инструкций на ARM называется Thumb. Так что это сильно отличается от CISC. Вы не будете выполнять изменение режима для выполнения короткой инструкции.
Сжатые наборы команд изменили правила игры для RISC. Некоторым вариантам RISC удается использовать меньше байтов, чем x86, для тех же программ, использующих эту стратегию.
Большие кеши
Кэш — это особая форма действительно быстрой памяти, которую вы можете поместить на кристалл вашего процессора. Это, конечно, отнимет у вашего процессора ценную кремниевую недвижимость, поэтому есть ограничения на то, сколько кеша вы можете добавить.
Идея кеширования заключается в том, что большинство реальных программ запускают небольшую часть программы гораздо чаще, чем остальную часть программы. Часто небольшие части программы повторяются бесчисленное количество раз, например, в случае циклов.
Таким образом, помещая эти часто используемые части вашей общей программы в кеш, вы можете значительно ускорить свои программы.
Это была ранняя стратегия RISC, когда программы RISC занимали больше памяти, чем программы CISC. Поскольку процессоры RISC были проще, для их реализации требовалось меньше транзисторов. Это оставило больше кремниевой недвижимости, которую можно было использовать для других вещей, таких как кэш.
Таким образом, имея большие кеши, процессоры RISC компенсировали то, что их программы несколько больше, чем программы CISC.
Однако со сжатием инструкций это, конечно, уже не так.
CISC наносит ответный удар — микрооперации
Конечно, CISC не сидел сложа руки и не позволял RISC превзойти себя. И Intel, и AMD разработали стратегии, имитирующие некоторые преимущества RISC.
В частности, им нужен был способ конвейеризации своих инструкций, который никогда не работал с традиционными инструкциями CISC.
Решение состояло в том, чтобы сделать внутреннюю часть ЦП CISC более похожей на RISC. Это было достигнуто за счет того, что декодированная инструкция разбивала инструкцию CISC на несколько более простых инструкций, называемых микрооперациями.
Как и инструкции RISC, эти микрооперации легче поместить в конвейер, поскольку они имеют меньше зависимостей друг от друга и выполняются в более предсказуемом количестве циклов.
Чем микрооперации отличаются от микрокода?
Микрокод — это небольшие программы ПЗУ, которые выполняются для имитации более сложной инструкции. Однако, в отличие от Микроопераций, они не помещаются в конвейер. Они не созданы для этой цели.
На самом деле микрокод и микрооперации обычно существуют бок о бок. В ЦП, использующем микрооперации, программы микрокода вместо прямого выполнения будут использоваться для генерации серии микроопераций, которые помещаются в конвейер для последующего выполнения.
Имейте в виду, что микрокод в традиционном ЦП CISC должен фактически выполнять декодирование и выполнение. По мере выполнения они берут под свой контроль различные ресурсы ЦП, такие как ALU, регистры и т. Д.
В современных CISC они завершают работу быстрее, потому что не используют ресурсы процессора. Они просто используются для создания серии микроопераций.
Чем микрооперации отличаются от инструкций RISC
Это обычное заблуждение. Люди думают, что микрооперация — это то же самое, что и инструкция RISC. Они совсем не такие.
Инструкция RISC существует на уровне ISA. Это то, на что нацелен компилятор. Они озабочены описанием того, что вы хотите сделать. И мы стараемся оптимизировать их, чтобы не использовать слишком много памяти и т. Д.
Микрооперация, напротив, совершенно другая. Микрооперации, как правило, большие. Они могут быть более 100 бит. Неважно, насколько они велики, потому что лишь некоторые из них существуют временно. Это отличается от инструкций RISC, которые составляют целые программы, потребляющие потенциально гигабайты данных. Они не могут быть сколь угодно длинными.
Микрооперации специфичны для конкретной модели процессора. Каждый бит имеет тенденцию указывать полностью определенные части ЦП, которые нужно включать или отключать при их выполнении.
Обычно, если вы увеличиваете инструкцию, вам не нужно никакого декодирования. Каждый бит может соответствовать определенному аппаратному ресурсу в ЦП.
Таким образом, разные процессоры с одним и тем же ISA могут иметь внутри разные микрооперации.
Фактически, сегодня многие высокопроизводительные RISC-процессоры превращают свои инструкции в микрооперации. Это потому, что микрооперации, как правило, даже проще, чем инструкции RISC. Но это не требование. Процессор ARM с меньшей производительностью может не использовать микрооперации, в то время как процессор ARM с более высокой производительностью с точно таким же набором инструкций может их использовать.
Преимущество RISC по-прежнему существует. Инструкции CISC ISA не были разработаны так, чтобы их было легко конвейерно. Следовательно, разбиение этих инструкций на микрооперации — сложная и запутанная задача, которая не всегда может хорошо работать. Перевод инструкций RISC в микрооперации обычно бывает более простым.
Фактически, некоторые процессоры RISC используют микрокод для некоторых своих инструкций, как и процессоры CISC. Одним из примеров этого является сохранение и восстановление регистров в отношении вызовов подпрограмм. Когда программа переходит к другой подпрограмме для выполнения задачи, эта подпрограмма будет использовать номер регистра для выполнения локальных вычислений. Код, вызывающий подпрограмму, не хочет, чтобы его регистры изменялись случайным образом, поэтому он должен часто сохранять их в памяти.
Это настолько частое явление, что добавление конкретной инструкции для сохранения нескольких регистров в память было слишком заманчивым. В противном случае эти инструкции могут съесть много памяти. Поскольку это предполагает повторный доступ к памяти, имеет смысл добавить это как программу микрокода.
Однако не все процессоры RISC делают это. RISC-V, например, пытается сказать более чистым и не имеет таких специальных инструкций. Микросхемы RISC-V очень ориентированы на оптимизацию ISA для конвейерной обработки. Более строгое следование философии RISC делает конвейерную обработку более эффективной.
Гиперпоточность или аппаратные потоки
Еще одна уловка, использованная CISC для возврата к RISC, заключалась в использовании гиперпоточности.
Помните, что микрооперации нелегко сделать чисто. Ваш конвейер по-прежнему, скорее всего, не будет заполняться так же регулярно, как конвейер RISC.
Уловка тогда заключается в использовании гиперпоточности. ЦП CISC принимает несколько потоков инструкций. Оба потока инструкций будут разорваны на части и превращены в микрооперации.
Поскольку этот процесс несовершенен, вы получите ряд пробелов в конвейере. Но, имея дополнительный поток инструкций, вы можете вставлять другие микрооперации в эти ограничения и, таким образом, поддерживать конвейер заполненным.
Эта тактика на самом деле также полезна для процессора RISC, потому что не каждая инструкция RISC может выполняться за один и тот же период времени. Например, доступ к памяти часто занимает больше времени. То же самое касается сохранения и восстановления регистров со сложными микрокодированными инструкциями, которые используют некоторые процессоры RISC. В коде также будут скачки, которые вызовут пробелы в конвейере.
Следовательно, более продвинутые и высокопроизводительные процессоры RISC, такие как процессоры IBM POWER, также будут использовать аппаратные потоки.
Однако я понимаю, что гиперпоточность — это уловка, которая больше приносит пользу CISC. Поскольку создание микроопераций на CISC менее совершено, они получают больше пробелов, которые нужно заполнить, и, следовательно, гиперпоточность может еще больше повысить производительность.
Если ваши конвейеры остаются заполненными, от гиперпоточности / аппаратных потоков нет ничего.
Аппаратные потоки также могут представлять угрозу безопасности. Intel столкнулась с проблемами безопасности аппаратных потоков, потому что один поток инструкций может влиять на другой. Подробностей этого я не знаю. Но, очевидно, некоторые поставщики по этой причине предпочитают отключать аппаратные потоки.
Аппаратные потоки, как правило, дают прирост скорости примерно на 20%. Таким образом, 5-ядерный ЦП с аппаратными потоками работает аналогично 6-ядерному ЦП без аппаратных потоков. Но, как я уже сказал, это число будет во многом зависеть от архитектуры вашего процессора.
В любом случае, это одна из причин, по которой ряд производителей высокопроизводительных чипов ARM, таких как Ampere, выпускают 80-ядерный процессор Ampere Altra , в котором не используется аппаратная потоковая передача. На самом деле я не уверен, использует ли какой-либо процессор ARM аппаратную потоковую передачу.
Ampere предназначен для использования в центрах обработки данных, где важна безопасность.
Имеет ли смысл различие между RISC и CISC?
Да, несмотря на то, что люди говорят, это все еще принципиально разные философии. Это может не иметь большого значения для высокопроизводительных чипов, поскольку у них такое большое количество транзисторов, что сложность разделения сложных инструкций x86 затмевается всем остальным.
Однако эти чипы все равно выглядят совсем по-другому, и вы подходите к ним по-другому.
Некоторые характеристики RISC больше не имеют особого смысла. Наборы команд RISC больше не обязательно так уж и малы. Конечно, это во многом зависит от того, как вы считаете.
Взгляд на RISC-V может дать хорошее представление о разнице. RISC-V основан на идее возможности адаптировать создание конкретных микросхем, где вы можете выбирать, какие расширения набора команд вы используете.
Однако есть базовый минимальный набор инструкций, и он очень похож на RISC:
- Исправленный размер
- Инструкции, разработанные для предсказуемого использования определенных частей ЦП для облегчения конвейерной обработки.
- Загрузить / сохранить архитектуру. Большинство инструкций работают с регистрами. Загрузка и сохранение в памяти обычно выполняется с помощью специальных инструкций только для этой цели.
- Множество регистров, чтобы избежать частого обращения к памяти.
Инструкции CISC, напротив, имеют переменную длину. Люди могут утверждать, что микрооперации похожи на RISC, но микрокод — это деталь реализации, очень близкая к аппаратной.
Одна из ключевых идей RISC — переложить тяжелую работу на компилятор. Это все еще так. Компилятор не может перестроить микрооперации для оптимального выполнения.
Время более критично при выполнении микроопераций, чем при компиляции. Это очевидное преимущество, позволяющее передовым компиляторам перестраивать код вместо того, чтобы полагаться на драгоценный кремний для этого.
В то время как процессоры RISC с годами получили более специализированные инструкции, например, для векторной обработки. Им по-прежнему не хватает сложности режимов доступа к памяти, которые есть у многих инструкций CISC.
Источники и дальнейшие исследования
Источники для этой статьи, которые я использовал для написания, собраны в этой предыдущей статье о среде .
Я бы также указал на следующие источники:
- RISC против CISC. Все еще имеет значение , Пол ДеМоне.
- Архитектура набора команд .
- РИСК
- Intel 8086
- О производительности ARM — Ксавье Тобин.
- Формат сжатого набора команд RISC-V .
- Видеопрезентация того, насколько хорошо работает сжатие инструкций RISC-V, с помощью тестов.
- Классический RISC-конвейер . Более подробно рассказывается о том, как наборы инструкций RISC разработаны для работы с конвейерами. Что делается на каждом этапе и т. Д.
- Регистр статуса . Я не обсуждал эту тему, но мне интересно узнать больше о компромиссах для различных архитектур RISC и конвейерной обработки. Многие процессоры RISC, например, не имеют флагов состояния для арифметических операций, только флагов общего назначения.
{kind=link}